멀티 코어 환경에서 하나의 작업을 분할해서 각각의 코어가 병렬적으로 처리하는 것을 말하는데, 병령 처리의 목적은 작업 시간을 줄이기 위함.
병렬처리 작업의 방법에는 2가지가 존재하며 멀티스레드 동작 방식 이라는 점에서는 동일하지만 서로 다른 목적을 가지고 있다.
| 구분 | 동시성 | 병렬성 |
| 동작 방식 | 멀티 스레드 방식 | |
| 목적 | 멀티 스레드가 작업을 번갈아가며 실행 | 멀티 코어를 이용한 동시 작업 |
ex. 쿼드 코어(4개 코어)CPU일 경우 4개의 서브 요소들로 나누고 4개의 스레드가 각각의 서브 요소들을 병렬 처리 함.
병렬 스트림은 요소를 처리하기 위해 포크조인 프레임워크(FF:ForkJoin Framework) 를 사용한다. 런타임 중에 FF가 동작하는데 포크 단계에서는 전체 데이터를 서브데이터로 분리한다. 그 후 분리된 서브 데이터를 멀티 코어에서 병렬로 처리하고 마지막으로 조인 단계에서 서브 결과를 결함해서 최종결과를 만들어 낸다.
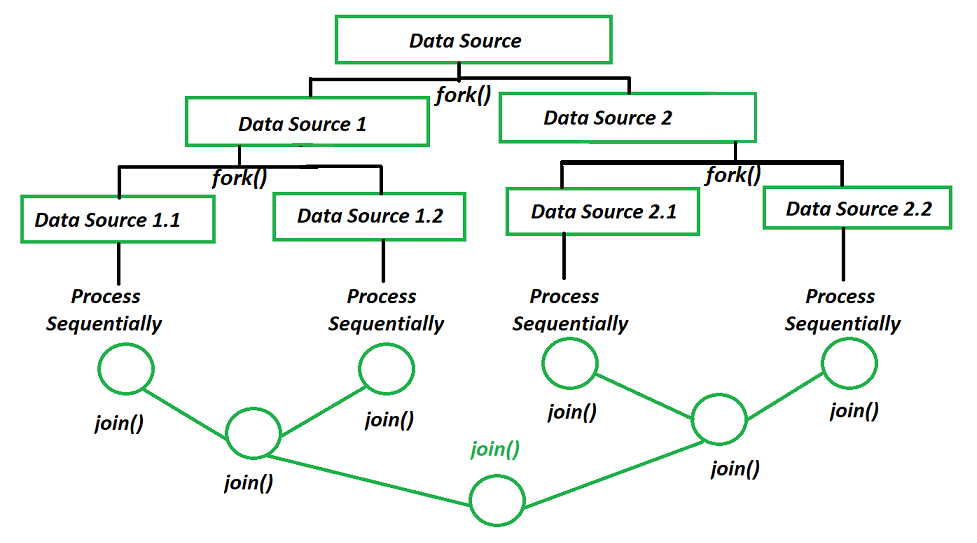
스트림 병렬 처리가 스트림 순차 처리보다 항상 실행성능이 좋은 것은 아니다.
Collection에 요소의 수가 적고 요소당 처리 시간이 짧으면 순차 처리가 오히려 병렬 처리보다 빠를 수 있다. 병렬처리 작업은 추가적인 비용(스레드풀 생성, 스레드 생성)이 발생한다.
스트림 소스의 종류 ArrayList, Array은 인덱스로 요소를 관리하기 때문에 포크 단계에서는 요소를 쉽게 분리할 수 있어 병렬 처리 시간을 줄일 수 있다. 그러나 HashSet, TreeSet 처럼 인덱스 요소가 없는 경우와 LinkedList 처럼 링크를 따라 요소를 구분해야하는 경우는 요소의 분리가 어려워 병렬처리가 늦어지게 된다.
코어 수
코어의 수만큼 병렬 처리(데이터 병렬 방식) 작업 수를 늘릴 수 있어 처리 속도를 늘릴 수 있다.

